
In keeping with the name of this site, this post will be a few random EPM items. I believe each to be useful information, but not necessarily needing a dedicated post by themselves.
PeriodsToDate Function
The function PeriodsToDate can be a very useful function. It is commonly used in a View dimension to get QTD and YTD values. However, when used on an account, performance can suffer. We had a situation where PeriodsToDate was used on the account for cumulative retained earnings.
SUM(PeriodsToDate([Period].Generations(2 ),[Period].CurrentMember),([NetInc],[Base]))
The formula correctly calculated retained earnings for each period, but the client was suffering with retrieval times over 30 seconds in ad hoc queries. We changed the logic to this:
CASE
WHEN IS([Jan],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base])
WHEN IS([Feb],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base])
WHEN IS([Mar],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base])
WHEN IS([Apr],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base])
WHEN IS([May],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base])
WHEN IS([Jun],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base])
WHEN IS([Jul],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base])
WHEN IS([Aug],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base]) + ([Aug],[NetInc],[Base])
WHEN IS([Sep],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base]) + ([Aug],[NetInc],[Base]) + ([Sep],[NetInc],[Base])
WHEN IS([Oct],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base]) + ([Aug],[NetInc],[Base]) + ([Sep],[NetInc],[Base]) + ([Oct],[NetInc],[Base])
WHEN IS([Nov],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base]) + ([Aug],[NetInc],[Base]) + ([Sep],[NetInc],[Base]) + ([Oct],[NetInc],[Base]) + ([Nov],[NetInc],[Base])
WHEN IS([Dec],[Period].CurrentMember) THEN
([Jan],[NetInc],[Base]) + ([Feb],[NetInc],[Base]) + ([Mar],[NetInc],[Base]) + ([Apr],[NetInc],[Base]) + ([May],[NetInc],[Base]) + ([Jun],[NetInc],[Base]) + ([Jul],[NetInc],[Base]) + ([Aug],[NetInc],[Base]) + ([Sep],[NetInc],[Base]) + ([Oct],[NetInc],[Base]) + ([Nov],[NetInc],[Base]) + ([Dec],[NetInc],[Base])
END
While not as neat and pretty as using the function PeriodsToDate, we were able to improve retrieval times by approximately 60%.
Lesson learned: Just because a function exists doesn’t mean it’s the best solution.
#SQL in Data Management Mapping
Data Management is a pretty cool product in the Oracle EPM world, at least I think it is. One can do a lot with it. But there are some quirks, one of which is trying to map empty values. Oracle documentation details using <BLANK> in the data map for instances where the source value is empty. Unfortunately, it doesn’t work. After scratching my head for what seemed like days and Googling everything I could think of, a very wise colleague suggested using SQL. I had not used SQL statements in data mapping before, but it turns out to be very easy.
Often, a mapping is something like this:
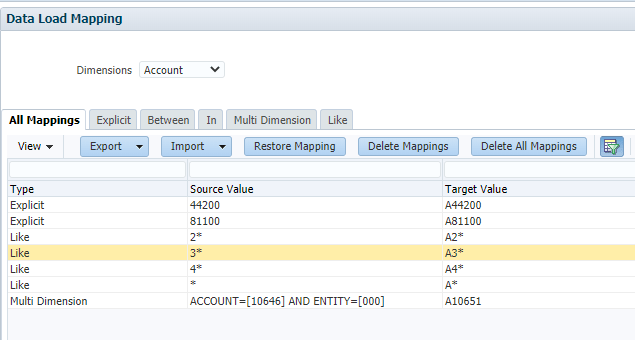
In my situation, I needed to map all departments with the same value and prefix with a “D”.
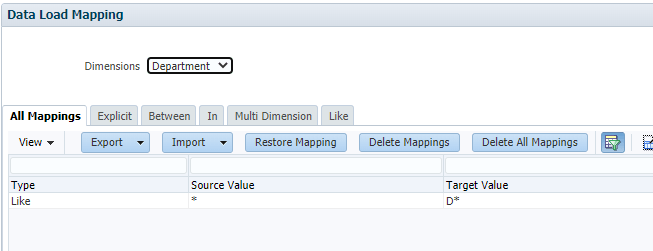
But since the source file had rows without values for department, this mapping resulted in a validation error, the mapping assigned a target value of just “D” to those rows.
I added another Like mapping as <BLANK> to “No_Department”.
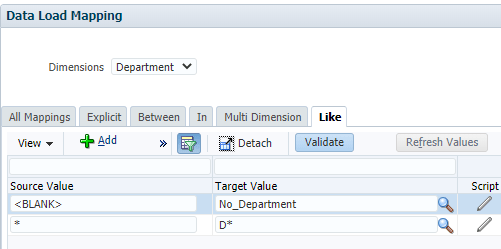
Sadly, <BLANK> does not work even though that is what is in the documentation. Neither does <NULL>.
Changing the mapping to use a SQL statement correctly identifies the rows without values for department and assigns them to “No_Department”.
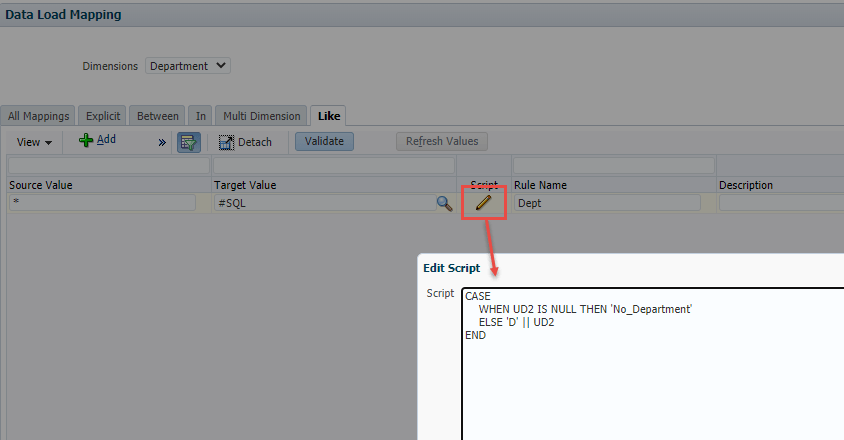
Lesson learned: Similar to our previous lesson, just because a feature is documented doesn’t mean it works.
Management Reporting (MR) Data Source
While developing MR reports, I find it helpful to have real data for validation. Since I’m developing in Test, and the Test environment may not have complete or accurate data, this can be a pain. One option is to refresh Test with the most recent data from Prod, but that can be time consuming and could impact others who are in Test doing their own development. MR provides an easy way to solve this issue.
Create a second Data Source that points to Prod, leave the main Data Source pointing to Test.
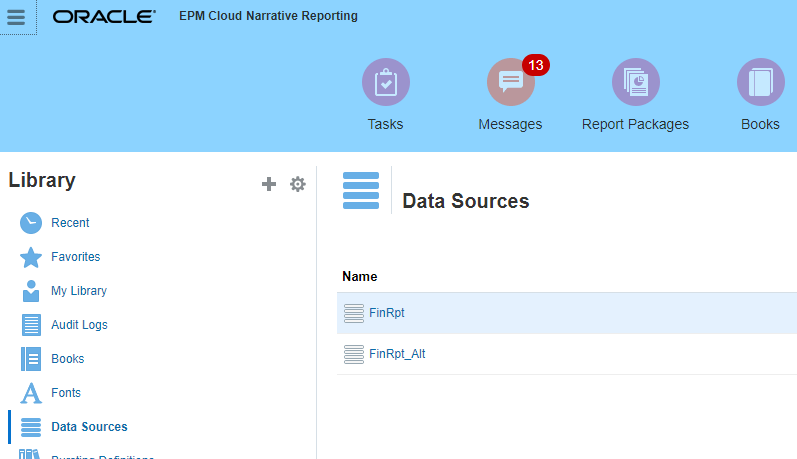
Primary Data Source is pointing to Test.
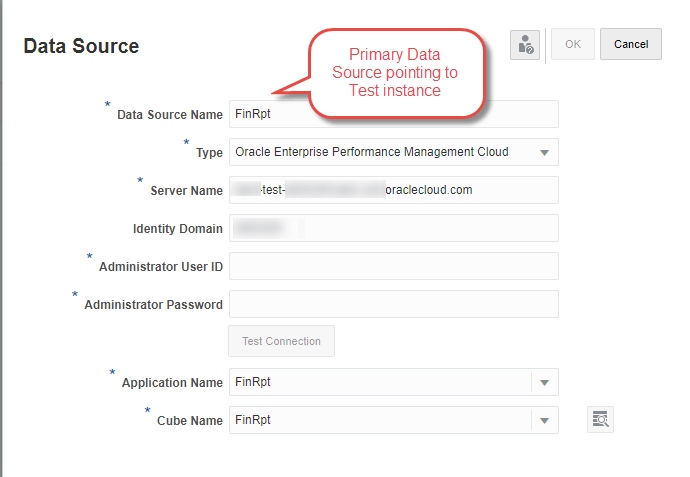
The new Data Source is pointing to Prod.
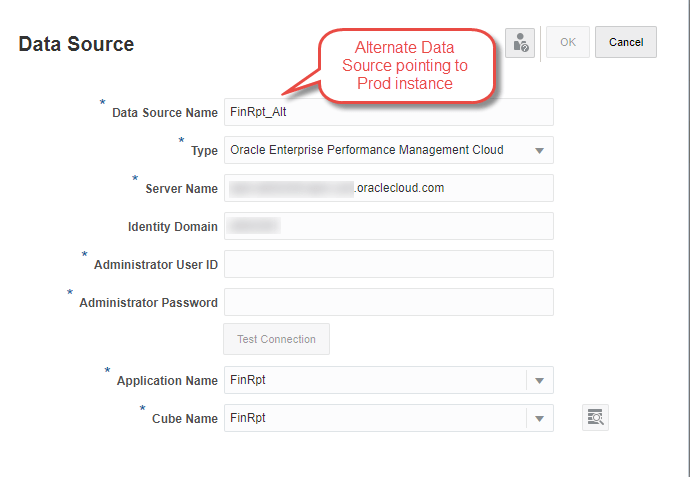
For any report that needs to be validated with current data from Prod, update the Data Source in the report.
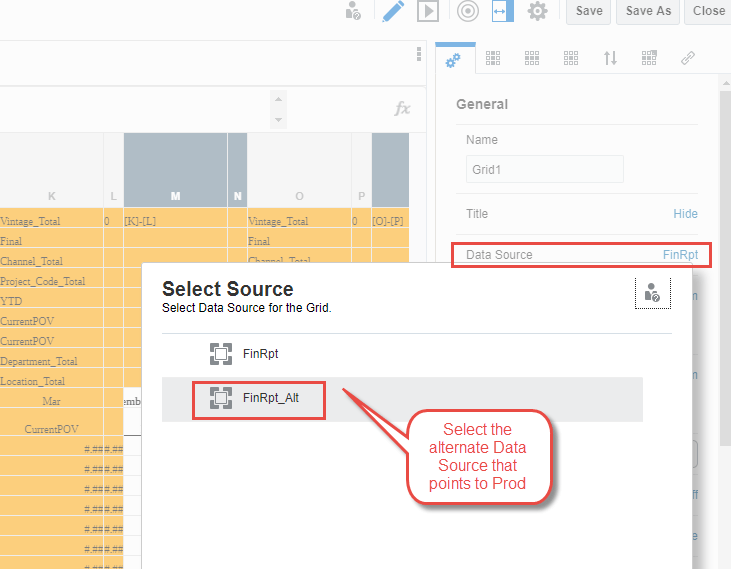
You can switch between the Data Sources for any reports as needed. Switch back to the primary before migrating a report to Prod. Assuming the Prod instance of MR has the same Data Source name, this makes it easier so you don’t have to update the migrated report.
That’s all for now, happy EPM’ng!
