We often have requirements for copying data between cubes, and many times this can be accomplished with data maps. We previously wrote about how to use Groovy for non-administrators to launch data maps. This works fine if the cubes are similar, for example, from the financials cube to a reporting cube with the same dimensionality and 1-to-1 member mapping. But what if the dimensionality between source and target is very different? Or within the same dimension the source and target members are different? One option is to use Data Integration (i.e., Data Management) and create an integration with all the necessary dimension and member mappings needed. But another option is to use Groovy for that mapping and copying of data from source to target.
As I’ve stated in previous posts on using Groovy, I’m still learning and hopefully getting better with each solution. Keep in mind that there is lots of information out there on using Groovy in EPM and there are most certainly other ways to do what I’m doing. This is what worked for me in this particular situation. Also, the intent of my Groovy posts is not to provide in depth understanding of the coding with Groovy (e.g., the technical aspects of the different commands), but rather a basic template that can be leveraged by others.
I needed to copy data from a Workforce cube to a Financials cube. The source had different dimensionality and differences between accounts, more than what could be managed with out-of-the box data pushes. The first step was to create the source grid. When designing a source grid, it can be helpful to think of it in terms of building an ad hoc Smart View query. The layout is essentially the same.

- Set the RTPS values in the first line. While it may work setting these values later in the code, it is better to do this first. These are basic run-time prompt values created in Calc Mgr.
- The source cube needs to be defined, in this case the source is OEP_WFP. Notice the case of the Groovy commands, it is a case sensitive language. Also, sourceCube and sourceBuilder values are user created, they don’t need to have the capitalization of the second words, but it does make reading easier.
- After defining the source cube, the POV is defined. Additionally, we are including a suppression of missing blocks to improve efficiency of the rule. The POV starts with identifying the dimensions, then the members are defined. RTPS values are used along with some hard coded member names.
- Next is defining the columns, first with the dimension and then the members.
- Last for the source grid is defining the rows. As with the POV and columns, first is the dimensions. Then the members are named. For Account, we are naming specific members. The same is being done for dimension PCN (the job code), specific members are named. The other dimensions for the rows are level0.
After defining the source grid, mappings are defined.
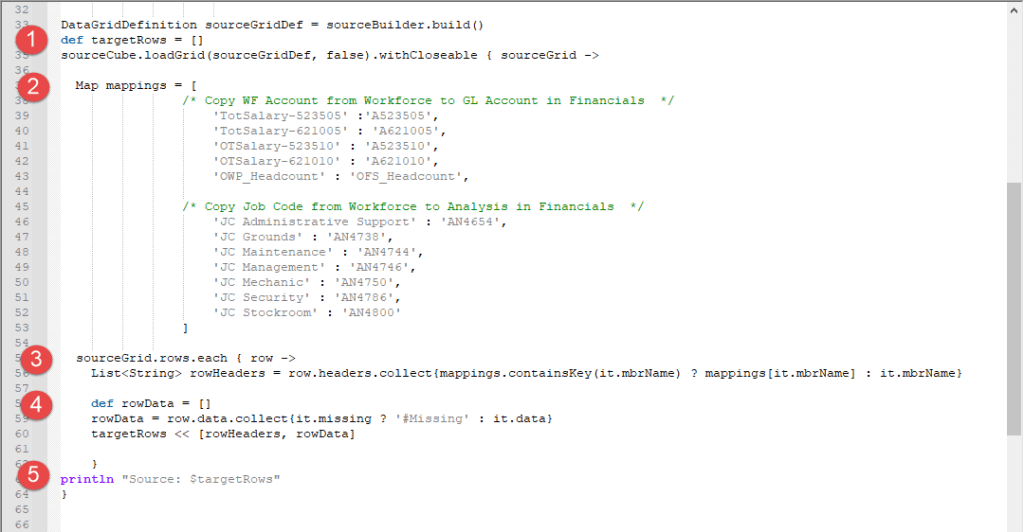
- First is to set the data grid, which is just creating a grid name that equals the source cube previously built. Target rows are also defined.
- Mappings are defined as the source member separated by a colon with the target member. The first grouping is for WFP accounts to the FS accounts. The second grouping is the WFP job code to the FS analysis members.
- Next is collecting the list of row mappings into the grid.
- Then the data is collected into the grid.
- A println is included to log the information and provide a validation for data captured and mapped.
So far, we have defined the source grid and the mappings. Now we can copy the data to the target.
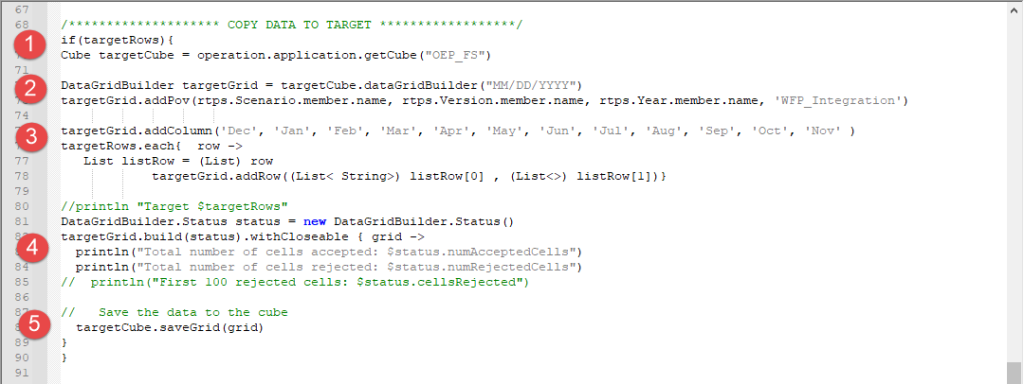
- The target cube is defined as OEP_FS.
- The target data grid is then defined using the target cube previously defined. This starts with the POV, similar to the POV defined in the source except with the dimensions of the target. We have a combination of run-time prompt values and a hard coded member.
- The columns are defined with hard coded members. Then the rows are defined as a list of the rows defined previously in the target grid section.
- Now the target grid is built and log information is generated.
- The last step is to save the grid with the data back to the database.
This is but one of likely many ways to use Groovy for copying data between cubes. One of the key benefits is that by using Groovy for the process, it does not matter if your source and target cubes are both BSO, both ASO, or one of each. The copy can go BSO to ASO or ASO to BSO. Also, member mappings can be very robust, the example given here is rather basic and straightforward. Concatenations, truncations, transformations, etc. can be used with the right coding. Maybe another post in the future with that kind of example. 😊
As always, happy EPM’ng!
Here is the full script:
/*RTPS: {Scenario}, {Version}, {Currency}, {Year}, {Company}, {Center}, {Location} */
/************* PREPARE SOURCE ************************/
Cube sourceCube = operation.application.getCube("OEP_WFP")
DataGridDefinitionBuilder sourceBuilder = sourceCube.dataGridDefinitionBuilder()
sourceBuilder.setSuppressMissingBlocks(true)
sourceBuilder.addPov(['Scenario', 'Version', 'Years', 'Employee', 'Property' ],
[ [rtps.Scenario.member.name], [rtps.Version.member.name], [rtps.Year.member.name], ['JC_Employees'], ['No Property'] ])
sourceBuilder.addColumn(['Period'], [ ['ILvl0Descendants("YearTotal")'] ])
sourceBuilder.addRow(['Account', 'PCN', 'Company', 'Center', 'Location', 'Currency'],
[
['TotSalary-523505', /* Salary - Ops Centers */
'TotSalary-621005', /* Salary - G&A Centers */
'OTSalary-523510', /* OT - Ops Centers */
'OTSalary-621010', /* OT - G&A Centers */
'OWP_Headcount'
],
['JC Administrative Support', 'JC Grounds',
'JC Maintenance', 'JC Management', 'JC Mechanic',
'JC Security', 'JC Stockroom'],
['ILvl0Descendants({Company})'],
['ILvl0Descendants({Center})'],
['ILvl0Descendants({Location})'],
['ILvl0Descendants({Currency})'+'No Currency'] // No Currency is used for the copy of the Hour data
])
DataGridDefinition sourceGridDef = sourceBuilder.build()
def targetRows = []
sourceCube.loadGrid(sourceGridDef, false).withCloseable { sourceGrid ->
Map mappings = [
/* Copy WF Account from Workforce to GL Account in Financials */
'TotSalary-523505' :'A523505',
'TotSalary-621005' : 'A621005',
'OTSalary-523510' : 'A523510',
'OTSalary-621010' : 'A621010',
'OWP_Headcount' : 'OFS_Headcount',
/* Copy Job Code from Workforce to Analysis in Financials */
'JC Administrative Support' : 'AN4654',
'JC Grounds' : 'AN4738',
'JC Maintenance' : 'AN4744',
'JC Management' : 'AN4746',
'JC Mechanic' : 'AN4750',
'JC Security' : 'AN4786',
'JC Stockroom' : 'AN4800'
]
sourceGrid.rows.each { row ->
List<String> rowHeaders = row.headers.collect{mappings.containsKey(it.mbrName) ? mappings[it.mbrName] : it.mbrName}
def rowData = []
rowData = row.data.collect{it.missing ? '#Missing' : it.data}
targetRows << [rowHeaders, rowData]
}
println "Source: $targetRows"
}
/******************** COPY DATA TO TARGET ******************/
if(targetRows){
Cube targetCube = operation.application.getCube("OEP_FS")
DataGridBuilder targetGrid = targetCube.dataGridBuilder("MM/DD/YYYY")
targetGrid.addPov(rtps.Scenario.member.name, rtps.Version.member.name, rtps.Year.member.name, 'WFP_Integration')
targetGrid.addColumn('Dec', 'Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov' )
targetRows.each{ row ->
List listRow = (List) row
targetGrid.addRow((List< String>) listRow[0] , (List<>) listRow[1])}
//println "Target $targetRows"
DataGridBuilder.Status status = new DataGridBuilder.Status()
targetGrid.build(status).withCloseable { grid ->
println("Total number of cells accepted: $status.numAcceptedCells")
println("Total number of cells rejected: $status.numRejectedCells")
// println("First 100 rejected cells: $status.cellsRejected")
// Save the data to the cube
targetCube.saveGrid(grid)
}
}

Hello there,
This is a super helpful article and I gained a lot of knowledge from it. As a follow-up, I did not see it in the script, but I am wondering how you handled clearing data from the target intersections before moving data to ensure that there are not excess values that may have previously been present in the source and moved to the target that are no longer present in the source?
Thanks,
Garren
LikeLike