
If you haven’t had the chance to use Auto Predict in EPM Planning yet, I suggest giving it a try. It is a robust tool that can provide valuable forecasting efficiencies once set up. You can even take it to a higher level by using the Insights functionality, but we’ll save that for another post in the future.
But as cool as Auto Predict is, there are some quirks with it. One of those oddities as noted here is that Auto Predict cannot use dynamic members as sources. There are other limitations on source data, such as the selection of history. As with any predictive tool, the prediction is only as good as the available history. Gaps in the history, or history that includes periods prior to a major change like a major acquisition, can be problematic.
Let’s start with the basics of what we want to predict. Our application is configured for 18-month rolling forecast. We want to predict a best, worst, and base case. Per Oracle documentation, to predict 18-months we need a minimum of 36 periods history. That means a forecast beginning November 2022 will use history back to November 2019. As I’m sure everyone remembers, 2020 was not a normal year. It’s safe to say that our history contains some significant inconsistencies.
For our purposes, 2019 is a better representation of data to include in the historical range. We could just extend our range to 4 years thereby including all of 2019. But that doesn’t resolve the inconsistencies of 2020. If it was one or two periods, it would probably smooth out adequately, but not 12 or more periods.
What we came up with as a solution was to create a “normalized” scenario for use in the prediction. The scenario Normalized Actual was prepopulated with data from Actual. Using a form with both scenarios then allows us to normalize the periods as needed by inputting to the Normalized Actual columns.
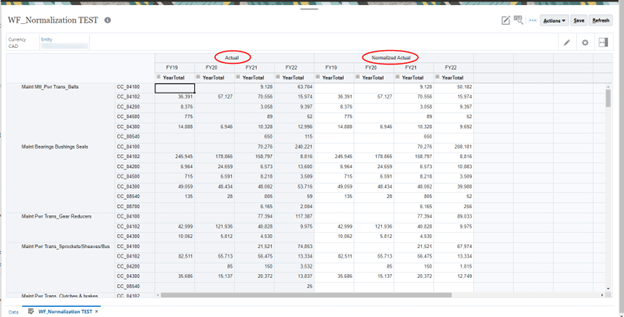
2020 updated.

Now that we have a better set of historical data, we can configure Auto Predict. From the home page, open the IPM card and select Configure.

Create a new prediction model or duplicate an existing model.

Name the prediction model and check the Auto Predict box. Leave the Generate Insights boxes unselected.
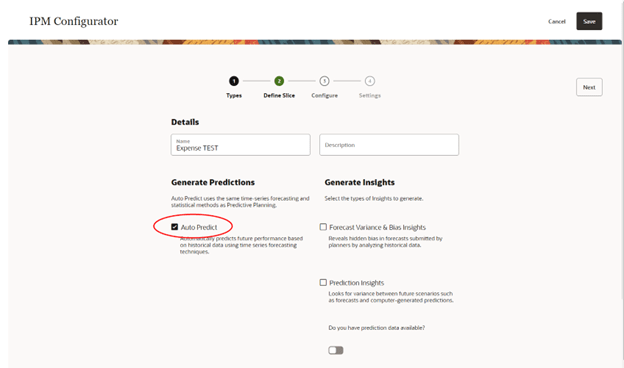
Go to the Define Slice tab. First, set up historical parameters.

- Select the source cube of the data. This can be any cube in the application.
- Select number of years for history. This can be from 1 to 5 years; Oracle suggests twice as many periods of history for the number of periods to predict.
- The scenario selection is the key to our goal of having consistent history for the prediction. If our history was not impacted by extraordinary events (i.e. a pandemic), we could just select Actual. Instead, we select the scenario we created for this purpose, Normalized Actual.
- Version and Plan Element are single members where the Normalized Actual data resides.
- The other source dimensions are using level0 members.
With the historical parameters set, we can now set the parameters for the predictions.
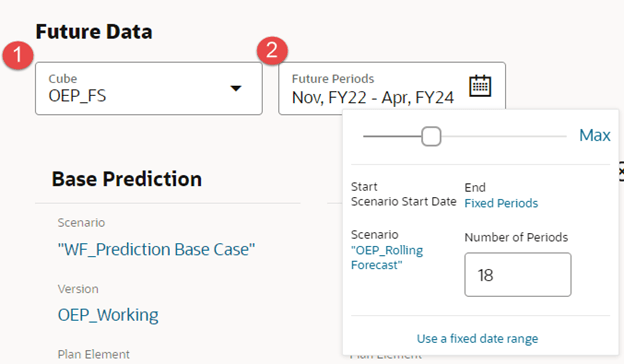
- Select the target cube.
- Select the range for the prediction. You can select a fixed start and end or a scenario-based range. Since we want to predict 18-month rolling forecast, we select scenario based with the Rolling Forecast scenario.
Continuing with the target parameters.
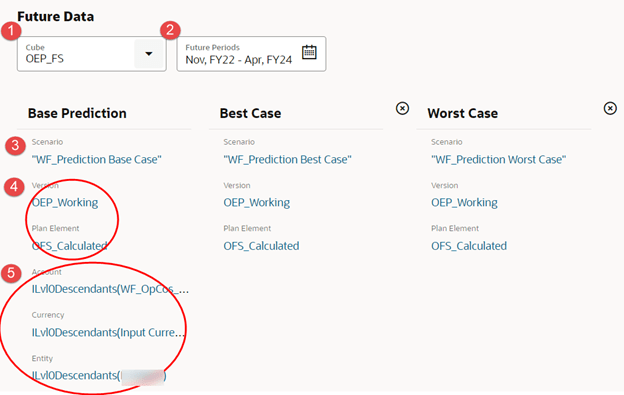
- As stated, we want to predict a best, worst, and base scenario. You could select just one or two, and it could save directly to the Rolling Forecast scenario. For our needs, we want to see the differences between predictions and decide which data to copy to our forecast. The scenarios Prediction Base, Prediction Best, and Prediction Worst were created specifically for this purpose. Note: We could have used different Versions instead of Scenarios.
- The Version selected is the same as the source. But the Plan Element target is different. The targets can be whichever members make sense for your use. Also, since these are single member source and target, each prediction can have different members for the targets.
- The other target dimensions automatically configure to match the source since they are using multiple members.
After the Define Slice tab is the Configure tab. The Oracle documentation has details on what each of these settings will do. These are the settings we decided to go with for this model.

Once all the configuration is completed, Save the model. The Auto Predict model is now ready to run.
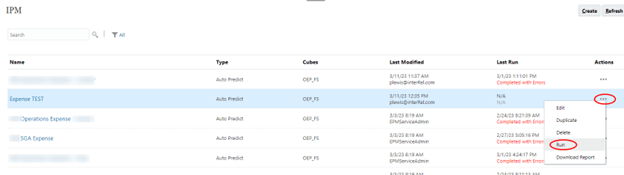
Once the model has been run, we can now view the predicted data and decide which data to use in our forecast. A form was created to show the prediction scenarios with the rolling forecast scenario.

You may have noticed that the forecast rows showing include accounts that are not in the prediction rows. The prediction rows are suppressed to hide zero data, but the forecast rows are not suppressed since we need the ability to input data where there may not be a prediction.
For the forecast rows that do have a prediction, we could type in the data from the appropriate prediction or copy the individual cells (very easy if viewing the form in Smart View), or use a business rule to copy the data for multiple rows. We have a business rule attached to an Action Menu. Right clicking on a row brings up the menu.
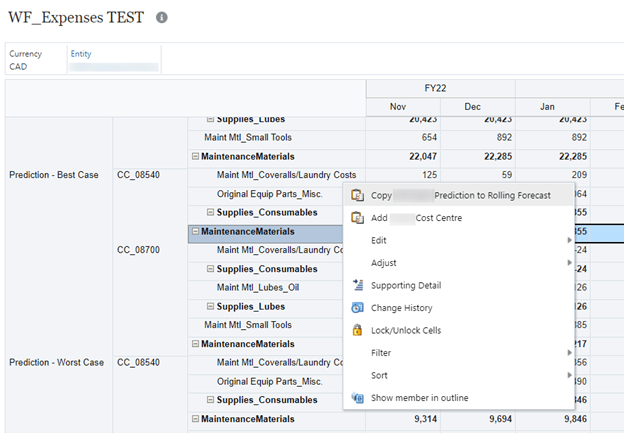
A prompt window opens with the selections prepopulated from the row where we did our right click. Having the window open like this allows the user to confirm the selections. The product line, cost centre, and account can be single members or parents.

The rule itself is pretty straightforward, here it is for reference.
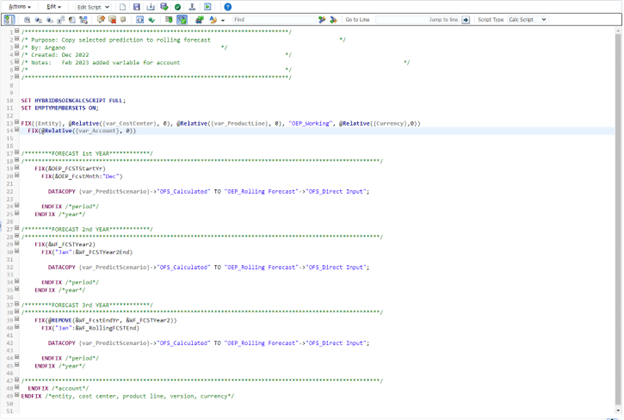
And there you have it, a way to normalize inconsistent history for use in an Auto Predict model. As is always the case with EPM, there may be other ways to accomplish this, but this is what worked in our situation. I’m hopeful that Oracle will continue to improve this functionality so this kind of workaround wouldn’t be needed. For example, allowing a more precise selection of source periods so we could skip the unwanted data. And allowing the selection of dynamic members in the source, that would be very useful so we could use Plan Element member Total Plan.
As always, happy EPM’ng!

One thought on “Using Auto Predict with Inconsistent History”